What is Bias and Variance Tradeoff
You don't want the model to over- or under-fit. You have to strive to find the right balance between the two. That is the bias-variance tradeoff.
The term bias was introduced by Mitchell in 1980
“[...] any basis for choosing one generalization over another, other than strict consistency with the observed training instances.”
In his paper, Mitchell argues that bias is necessary, in certain cases, for an inductive leap.
It was not until 1992 that Geman et al. introduced the bias-variance trade-off.
What is Bias
If you do a search for the term bias in machine learning, you might come across multiple meanings. The bias we are talking about, bias-variance, measures the error introduced by simplifying assumptions in the model.
Statistical bias is a consistent error a model makes, regardless of the amount of data it has. Even with a large training set, the model will repeatedly produce incorrect answers in the same way.
In the bias–variance framework, bias measures the difference between the model’s expected prediction and the true underlying function.
When the model is highly biased, it oversimplifies predictions, missing important trends, and creates a linear pattern, failing to represent the complexity of the dataset.
This leads to what we call underfitting.

What is Variance
Variance is the opposite of bias. It is when the model picks up too much information, or noise, along with the trend, making it too complex. We also call it overfitting.
That means the model will perform well on the training data but will have high errors on the test data.
When the variance is high, the training error from our model will be nearly zero. You might think that is a great thing. But once you run the model against the test data, you will realize that it’s overfitting.
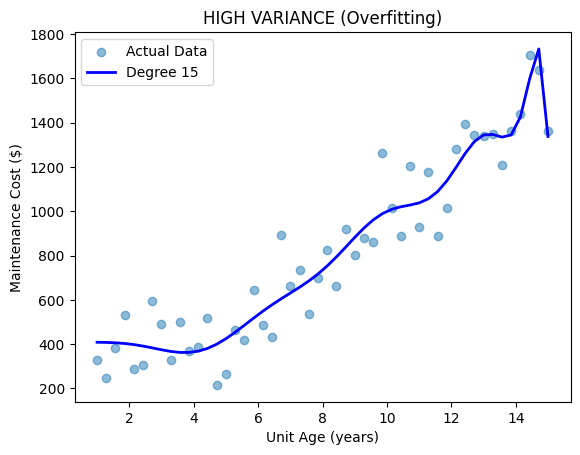
In essence, our model is learning irrelevant information from the training data. It is picking up a lot of noise and overlooking the real trend.
What is Bias/Variance Tradeoff
You don’t want the model to over- or under-fit. You have to strive to find the right balance between the two. That is the bias-variance tradeoff.
The model can’t be too simple or too complex. We want something with enough complexity to learn the generalization of the patterns in the data.
The two concepts are polar opposites. When bias is reduced, variance increases. And vice versa.
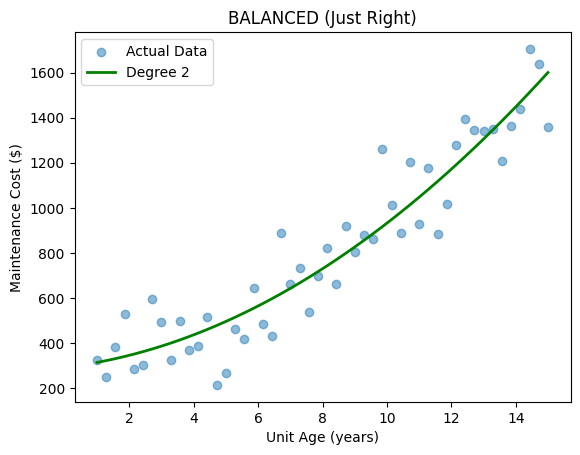
In an ideal world, you are looking for low bias and low variance. But if lowering one increases the other, how could you have both at a low level?
That’s why it is called a tradeoff. You trade bias for variance till you can balance those out.
Navigating the tradeoff in practice comes down to a few core tools.
Regularization techniques like Ridge and Lasso penalize model complexity, pulling an overfit model back toward simplicity by shrinking coefficients.
Cross-validation lets you observe the gap between training and test error directly. If there is a widening gap, that’s your signal that variance is taking over.
Ensemble methods like Random Forest and Gradient Boosting attack the problem from both sides simultaneously, using averaging to reduce variance while combining weak learners to reduce bias.
Keep in mind that none of these are silver bullets. Nothing in data science is. But together they give you the levers you need to push the model toward that middle ground where generalization actually lives.
No comments yet. Be the first.